Discover the power of Microsoft Fabric in automating data warehousing with our latest video, “Microsoft Fabric creates a Warehouse Automatically”. This informative video demonstrates how you can effortlessly create a data warehouse without the need for complex and time-consuming traditional warehousing processes.
Join us as we explore how Microsoft Fabric automatically generates a default data warehouse, showcasing the transformation of Delta tables into accessible tables within the warehouse. Learn step-by-step how to create Delta tables in the lakehouse, enabling their visibility as fully functional tables in the data warehouse.
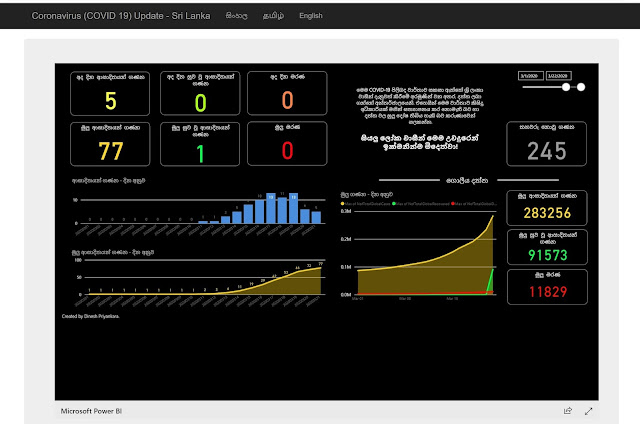
Furthermore, we explore the flexibility of the data warehouse, demonstrating how you can enhance it by creating custom views and stored procedures. Additionally, we demonstrate the way of opening the warehouse as the default Power BI dataset for creating reports and dashboard.
Don't miss out on this informative video that provides valuable insights into Microsoft Fabric's data warehousing capabilities. Subscribe to our channel for more in-depth tutorials and stay up to date with the latest advancements in data management and analytics.