This video discusses performing data science experiments in SQL Server using Python. Setting up the environment, training, storing models and consuming trained models stored in the database are discussed with a demonstration.
Showing posts with label Microsoft SQL Server. Show all posts
Showing posts with label Microsoft SQL Server. Show all posts
Wednesday, April 8, 2020
Friday, October 20, 2017
Azure Marketplace - SQL Server 2016 Virtual Machine - Data Tools cannot be installed
As you know, easiest way of getting a SQL Server set up in Azure is, purchasing a Virtual Machine in the Marketplace. There are multiple VMs for SQL Server based on Standard, Enterprise and Developer editions, you can pick the one as per your requirements.
Remember, it does not come with all tools. It has Management Studio installed but it does not have Data Tools installed, hence it needs to be installed.
I had configured a SQL Server 2016 SP1 VM and have been using for sometime. There was no requirement for Data Tools but I experienced an issue when I try to install Data Tools using standard Setup.exe.

I noticed that Setup fails when it tries to download required components from Microsoft site.

......Error 0x80072f08: Failed to send request to URL: https://go.microsoft.com/fwlink/?LinkId=832089&clcid=0x409...............
I did not immediately identify the issue but with my fellow MVPs' help, I realized that it can happen with a block related to security.
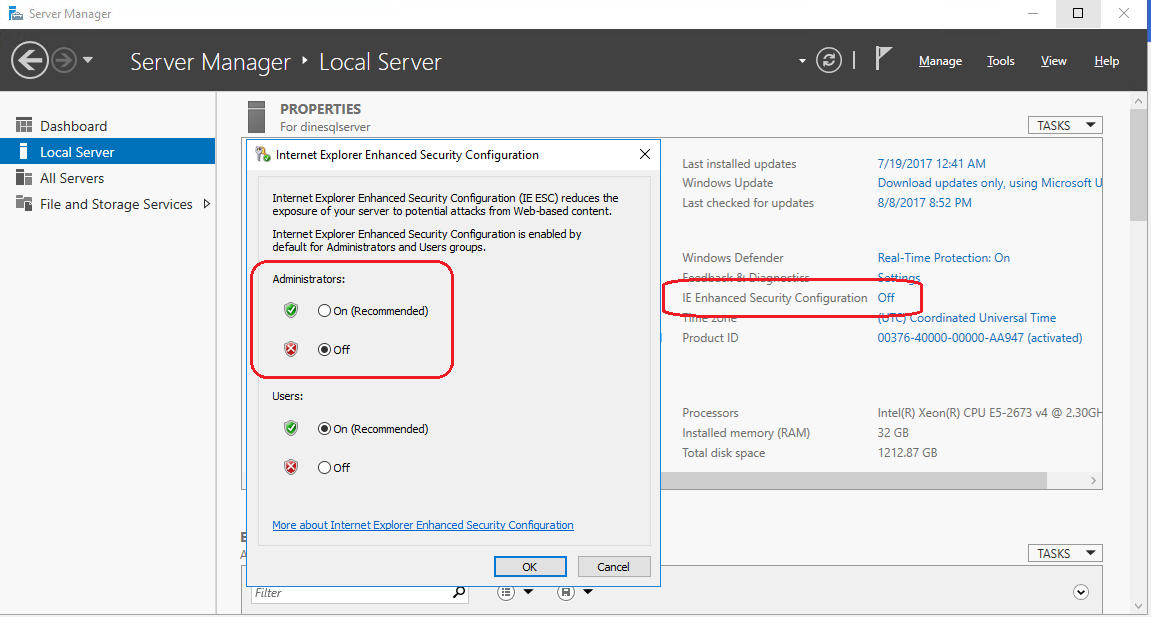
If you face the same, make sure that no firewall settings block required site and Administrator (or whoever run) has no restrictions. You can make sure that Administrator has no restrictions by checking Server Manager - Local Server - IE enhanced security configuration.
Wednesday, July 20, 2016
Handout to Resolve SQL Server Connectivity Issues [Guest Post]
This post is written by Andrew Jackson.
Problem Statement
While launching Microsoft SQL Server Management Studio, sometimes user faces a problem when they try to connect with the server. After clicking on Connect button, an error message box appears, which indicates that there is some connectivity issues in the server.
End user becomes tensed when they find it impossible to connect with the server and such errors are known as SQL server connectivity issues. In this blog, we are going to discuss that why does these connectivity issues occurs and what are the measures to troubleshoot them.
Causes of Connectivity Issues in SQL Server
Generally, when one fails to connect to the SQL server, the reasons may be:
- The network of SQL server may be disconnected or slow
- The SQL server of machine may be improperly configured
- There must be some problem with firewall or other network devices
- The connection between two servers may be disconnected
- Applications related to the server may be improperly configured
- There may be authentication error or log-in issue on the server
Approaches To Resolve The Problem
In this section, we are going to discuss different techniques to resolve SQL server connectivity issues. Follow the below-mentioned procedure for resolving your problem:
NOTE: After performing each step, restart your machine and then try to connect to the server. If you are successfully connected to the server, then stop your procedure there only; else go to next step.
STEP 1: Resolving Networking Issue
As discussed earlier that network connection could be the one reason for connectivity error because a stable network is being required for establishing a remote connection. Therefore, the first approach should be to examine the network by executing the following commands (given in the snapshot):

STEP 2: Modify the SQL Server Configuration
Use SQL Server Configuration Manager for examining the protocols, which are used for running targeted SQL server. The server supports TCP protocol, Shared memory, and Named Pipes. If the protocols are disabled, then enable them by making use of Configuration manager. After performing configuration, restart your SQL server machine.
STEP 3: Improving Network Devices Functioning
Network devices like firewall, routers, gateway, etc., may be settled in such a way that they block the connection request. The rules of firewall may be configured in such a way that it blocks the request of SQL connection. Therefore, for resolving such error you will have to disable the functioning of firewall because if the firewall is disabled, then its will stop its functioning & hence, you will be able to connect with SQL server. Moreover, after having a successful connection, you can again enable the functioning of the firewall.
STEP 4: Resolving the Client Driver Issue
This solution is applied on the client machine. Go through the following description to troubleshoot the SQL Server connectivity issues:
“Execute the below-shown command to log-in into another client computer via TCP protocol. If TCP is disabled, then enable it and then use SQL Management Studio, OSQL, and SQLCMD for testing SQL connections.”
STEP 5: Properly Configure SQL Related Applications
Once again reconfigure the applications related to SQL server and then go through the following assumptions:
- The application is running on your account or on a different account. If the application is running on the different account, then configure it within your account.
- Analyze your connection string and check whether the string is compatible with your driver or not. If not, then make it compatible with your driver.
STEP 6: Resolve Authentication & Log-in Faults
The last step or you can say the end approach to resolve the connectivity problem is to troubleshoot faults, which occurs at the time of authentication procedure and during log-in. It relates to a network connection, machine’s operating system, and the server database.
- Make sure that the input credentials are valid
- If you are using SQL auth, then mixed authentication should be enabled
- Examine all the eventlog of your machine and collect some more information
- Analyze the permissions whether they are enabled for logging into the account or not. If not, then instantly enable them.
After having a brief discussion about how to deal with SQL Server connectivity issues, one can wind up with the fact that these connectivity issues are due to fault in the network, network devices, or improper configuration. Therefore, one can troubleshoot the SQL connection error 40 and SQL error 26 by going through the mentioned steps.
Friday, November 27, 2015
Microsoft SQL Server Code Names for versions and features
Microsoft SQL Server team used/uses various code names for SQL Server versions and some of its features, here are some of them found in the web. I tried to match the best image can find in the web, not exactly sure whether it is the right picture, hence please let me know if I have used wrong pictures.
| Version/Feature | Code Name | |
|---|---|---|
| SQL Server 6.0 Enterprise Manager | Starfighter | |
| SQL Server 6.0 Agent | Starfighter II | |
| SQL Server 6.5 |  | |
| SQL Server 7.0 | Sphinx |  |
| SQL Server 7.0 OLAP Services | Plato |  |
| SQL Server 2000 (32-bit) | Shiloh | |
| SQL Server 2000 (64-bit) | Liberty |  |
| SQL Server Reporting Services 2008 | Rosetta |  |
| SQL Server 2005 | Yukon |  |
| SQL Server Analysis Services 2005 | Picasso |  |
| Database Design and Query Tools | DaVinci |  |
| SQL Server 2005 Mobile Edition | Laguna |  |
| SQL Server 2008 | Katmai |  |
| SQL Report Designer 2.0 | Blue | |
| SQL Server 2008 R2 | Killimanjaro |  |
| SQL Server 2012 | Denali |  |
| SQL Server Developers (Data) Tools | Juneau |  |
| SQL Server Columnstore Index | Appollo |  |
| SQL Server 2014 (In-memory OLTP) | Hekaton |  |
Sunday, July 12, 2015
SQL Server: Locking cost, concurrency cost and concurrency issues [Discussion on Transactions - III]
Continuing notes related to the discussion....
Another area that was discussed is, how SQL Server places locks for transactions and whether the cost of transaction goes up based on the locking mode used. What exactly happens when we query, when we execute an action query? By default, SQL Server decides what type of locking mode should be used for our query, whether it should be shared or exclusive, and the type of resources should be locked: RID, Pages, Tables, Database, etc.
If SQL Server has to maintain many number of locks, the maintenance cost goes up and it might affect to the performance too. However this might increases the concurrency. For example, assume that we update 6,000 records in a table. Considering many factors, SQL Server might first obtain fine-grained-locks (row or page level locks) only for records that are being updated. This makes sure that other records in the table are not locked and can be accessed by other users, increasing the concurrency, reducing the concurrency cost. However, the cost of maintaining 6,000 locks may be very high. If SQL Server detects that the cost is higher than expected, it tries to escalate the fine-grained-locks to more coarse-grained-locks (table level locks), decreasing the the locking cost and increasing the concurrency cost (more and more users will be blocked). Below diagram shows this;

This code shows how locks are obtained for a transaction that updates 5,000 records;
-- starting a transaction BEGIN TRAN; -- update 4000 records UPDATE TOP (4000) InternetSalesTest SET DiscountAmount = SalesAmount * (5/100) WHERE MONTH(OrderDate) = 5; -- check locks sp_lock;

Since only records that are being updated are locked, users can access other records without any issue. This increases the concurrency reducing the concurrency cost. However this increases locking cost.
When 6,000 records are getting updated;
-- rollback the previous transaction ROLLBACK TRAN; -- start a new transaction BEGIN TRAN; -- update 6,000 records UPDATE TOP (6000) InternetSalesTest SET DiscountAmount = SalesAmount * (5/100) WHERE MONTH(OrderDate) = 5; -- check locks sp_lock;

Since the entire table is locked now, it decreases concurrency increasing concurrency cost. No other users can access the table though locking cost is low now.
This is changeable however it is always recommended not to change the default behavior unless you know what you exactly do.
We discussed about concurrency issues too. There are four well known issues related to concurrency which can be addressed with changing locking mechanism by applying Isolation Level. There are Dirty read, Lost updates, Inconsistency Analysis, and Phantom reads.
I have written an article on this in 2011, you can have a look on it at: http://www.sql-server-performance.com/2007/isolation-levels-2005/
Friday, July 10, 2015
Understanding SQL Server Recovery Process [Discussion on Transactions - II]
This is the continuation of the post I made: Understanding transaction properties with Microsoft SQL Server.
During the same discussion, we talked about how SQL Server handles incomplete transactions in the event of a power failure or system crash. In order to understand this, we need to understand a process called Recovery Process. This process takes place every time SQL Server is started or when a restore operation is performed.
Recovery Process makes sure that incomplete transactions are either rolled back or rolled forward. This is possible because necessary information is available in the log file even though data files are not updated with modifications performed by our transactions. When a modification is performed, log is updated with information such as values related to the modification, type of the change, page numbers, date and time of the beginning and end. SQL Server makes sure that the message that says “transaction is completed” is sent to the client only after relevant information is written to the log. Remember, physical log is immediately updated with our transactions but it does not update data pages in the disk (data files) immediately. It updates data pages loaded to the buffer and pages in the disk are updated by a process called Checkpoint.
Checkpoint writes updated data pages in the memory to data files. In addition to that, it updates the log file with information related to transactions that are in progress.
When Recovery Process runs, it checks for transactions that have updated the log but not updated the data file. If found, it redoes the transactions applying modifications recorded in the log to data files. This is called as redo phase of recovery.
If Recovery Process finds incomplete transactions in the log file, it checks for updated data pages in the data file related to the transaction and using information available in the log file, it undoes all modifications from the data file. This is called as undo phase of recovery.
This video shows how Recovery Process works with complete and incomplete transactions. It shows how transactions are started with the time line, how log is updated (with ) and how data files are updated (with ). And finally, it shows how Recovery Process works on all transactions and recover them either performing Redo or Undo.
Tuesday, July 7, 2015
Understanding transaction properties with Microsoft SQL Server [Discussion on Transactions - I]
I had a chance to discuss an old topic with few of my colleagues, it was on transactions and isolation levels. Although it is old, well known to experienced engineers, it is something new and something important to know for many. Therefore, thought to make some notes on the discussion, here is the first one.
What is a transaction? Simplest way to understand it is, consider multiple operations to be done as a single operation. In database management system world, it is a unit of work that will contain one or more operations on querying, modifying data and modifying definition of the data. With SQL Server, we implement explicit transactions using BEGIN TRAN, COMMIT TRAN and ROLLBACK TRAN. In addition to that, SQL Server supports implicit transaction and auto-commit transactions.
Transactions have four properties. Here are details we discussed on them aligning with SQL Server.
Atomicity: Transaction is considered as an atomic unit of work. As explained above, it includes one or more operations. However transaction completion is not just completing one operation, it should either complete all operations involved or none of them should be completed. SQL Server automatically rolls back transactions that have errors if it runs with auto-commit mode and we need to roll back if explicit or implicit transactions are used. If the system fails before the completion of the transaction, upon restart the service, SQL Server undoes all incomplete transactions during Recovery Process.
Consistency: This refers the state of the data (or database). When a transaction needs to be started on data, data needs to be in a consistence state in order to access. In SQL Server, if data is being modified, with default behavior, the state of the data is not consistence and transaction has to wait, unless different isolation level is used. SQL Server allows to start the transaction once data is consistence and transaction goes through all integrity rules set and completes bringing data into another consistence state.
Isolation: This refers controlling data access as transaction expects. Basically, if transaction expects to get exclusive access even for data reading, this property makes sure that data is in required consistency level for accessing. Once allowed, if other concurrent transactions require same data, access is allowed based on the way data is being accessed by the first transaction. SQL Server offers two methods for handling isolation: locking and versioning. Both locking and versioning are available in on-premises SQL Server installation and default is locking. Locking makes sure that transaction cannot read data if it is inconsistence. Versioning is bit different, if data is inconsistence, it allows to read the previous consistence state of data. This is the default for Azure SQL Databases. This can be controlled by implementing different isolation levels with transactions.
Durability: Once the transaction is committed, it is considered as durable even with a disaster. SQL Server uses write-ahead mechanism for handling this, it makes sure committed transactions are written to the transaction log before writing it to data files. If something happens before writing committed data to the data file, still data can be recovered using info recorded in the log file. Generally, at the restart of SQL Server service, it checks the transaction logs for rolling forward transactions that are written to log but data files and rolling back transaction that are incomplete.
Thursday, March 5, 2015
How to load/insert large amount of data efficiently
Importing data from other sources is a very common operation with most of database solutions as not all data cannot be entered row-by-row. When large amount of data needs to be imported, we always consider about the constraints added to the table and minimal logging expecting improved performance.
SQL Server supports a set of tools for importing data: Import and Export Wizard, bcp (Bulk Copy Program), BULK INSERT, OPENROWSET (BULK). Preference always goes to either bcp or BULK INSERT, however, to improve the performance of it, some of the options have to be considered and set. This post explains how to load a large amount of data using bcp with various options.
For testing the best way, I created a database called TestDatabase and a table called dbo.Sales. I prepared a text file called Sales.txt that has 7,301,921 records matching with dbo.Sales table structure. The Recovery Model of the database is initial set as Full.
Then I loaded the table with following bcp commands. Note that each and every command was run after truncating and shrinking the log file.
--Loding without any specific option bcp TestDatabase.dbo.Sales in C:\Temp\Sales.txt -S DINESH-PC\SQL2014,8527 -T -c --Loding with TABLOACK option for forcing to lock the entire table bcp TestDatabase.dbo.Sales in C:\Temp\Sales.txt -S DINESH-PC\SQL2014,8527 -T -c -h "TABLOCK" --Loding with our own batch size bcp TestDatabase.dbo.Sales in C:\Temp\Sales.txt -S DINESH-PC\SQL2014,8527 -T -c -b 3000000 --Loding with our own batch size and TABLOCK bcp TestDatabase.dbo.Sales in C:\Temp\Sales.txt -S DINESH-PC\SQL2014,8527 -T -c -b 3000000 -h "TABLOCK"
Once the table is loaded four times, then the table was loaded again with Bulk Logged recovery model. All commands were executed just like previous one, making sure that log is truncated and shrunk before the execution.
Finally here is the result.
As you see, you can get improved performance in terms of the speed by setting the batch size and tablock with bulk-logged recovery model. If you really consider about log file growth, then tablock option with bulk-logged recovery model is the best.
I believe that BULK INSERT offers the same result, however it is yet to be tested in similar way.
| Command | Recovery Model | Time (ms) | Log file size after loading |
|---|---|---|---|
| With no specific option | Full | 189,968 | 3,164,032 KB |
| With TABLOCK | Full | 275,500 | 1,475,904 KB |
| With batchsize | Full | 108,500 | 2,377,088 KB |
| With batchsize and TABLOCK | Full | 99,609 | 1,964,480 KB |
| With no specific option | Bulk Logged | 140,422 | 3,164,032 KB |
| With TABLOCK | Bulk Logged | 239,938 | 26,816 KB |
| With batchsize | Bulk Logged | 121,828 | 2,377,088 KB |
| With batchsize and TABLOCK | Bulk Logged | 86,422 | 1,475,904 KB |
As you see, you can get improved performance in terms of the speed by setting the batch size and tablock with bulk-logged recovery model. If you really consider about log file growth, then tablock option with bulk-logged recovery model is the best.
I believe that BULK INSERT offers the same result, however it is yet to be tested in similar way.
Monday, March 2, 2015
Free Microsoft SQL Server preparation courses at Virtual Academy for exams 464 and 465
Microsoft Virtual Academy has added two new preparation courses for SQL Server exams. Theses two courses cover Developing Microsoft SQL Server Databases (464) and Designing Solutions for SQL Server (465). If you do not like to read articles or books, here is the way of learning areas related to these two exams, all courses are built with videos :).
- Developing Microsoft SQL Server Database (464) - 6 modules, approximately 7 hours.
- Designing Database Solutions for SQL Server (465) - 5 modules, approximately 6 hours.
In addition to these two, few more preparation courses related to other SQL Server exams are available;
- Implementing Data Models & Reports with Microsoft SQL Server (466) - 7 modules, approximately 8 hours.
- Designing BI Solutions with Microsoft SQL Server (467) - 6 modules, approximately 7 hours.
- Querying Microsoft SQL Server 2012 Databases (461) - 8 modules, approximately 7 hours.
- Administering Microsoft SQL Server 2012 (462) - 6 modules, approximately 7 hours.
- Implementing a Data Warehouse with SQL Server (463) - 6 modules, approximately 7 hours.
Sunday, March 1, 2015
SQL Server Brain Basher of the Week #001
I have been doing a series of session called SQL Server Brain Basher in SQL Server Sri Lanka User Group (https://www.facebook.com/groups/sqlserveruniverse/) that explains some tricky questions which we cannot answer immediately, unless you have excelled the area related. Thought to have at least one I used before (and planning to use in future) as a blog post in every week, hence, here is the first one which is fairly an easy one.
What would be result of following query?
SELECT 100, 200 '300';
If you are familiar with adding aliases to columns, you can immediately answer. This query returns two columns; first column with value of 100 without a column name, and second with a value of 200 with a column name of 300.

Column alias can be used to relabel column if required. This is really useful if you need to have a different name for the column without having the one coming from the table and name calculated columns. There are multiple ways of adding column aliases, here are some of the ways;
-- Column alias using AS keyword SELECT 100 AS Column1, 200 AS 'Column2'; -- Column alias with an Equal sign SELECT Column1 = 100, 'Column2' = 200; -- Column alias following column name SELECT 100 Column1, 200 'Column2';
Saturday, February 28, 2015
How to stop users seeing all databases by default
Here is the scenario. You have created a login called "Jane" and have not added to any server role. And you are 100% sure that she has not been given any permission on any database and she has no default database. Here is the statement you use:
Now she logs into SQL Server as below;

And she sees the object explore. Not only that she can expand the databases node and see databases.

Of course, she cannot go into a database and see the content but this is an issue for many cases, why should we let Jane to see even names of databases?
This becomes possible by default because of the Public server role. By default Public server role has permission on VIEW ANY DATABASE and all Logins are autmatically added to Public role.

If you need to stop this, change this permission like below (you can easily change this using GUI too).
Now Jane cannot see even names of databases unless she has permission on it.

CREATE LOGIN Jane WITH PASSWORD = 'Pa$$w0rd' , CHECK_POLICY = OFF;
Now she logs into SQL Server as below;
And she sees the object explore. Not only that she can expand the databases node and see databases.
Of course, she cannot go into a database and see the content but this is an issue for many cases, why should we let Jane to see even names of databases?
This becomes possible by default because of the Public server role. By default Public server role has permission on VIEW ANY DATABASE and all Logins are autmatically added to Public role.
If you need to stop this, change this permission like below (you can easily change this using GUI too).
DENY VIEW ANY DATABASE TO Public;
Now Jane cannot see even names of databases unless she has permission on it.
Friday, February 27, 2015
SQL Server Security Concepts: Securables, Pricipals and Permissions
When discussing and learning security related to SQL Server, it is always better to know the key concepts and terms related to it. Some of the concepts are not only related to SQL Server, they are related to almost all applications in terms of security. In simplest way, security is all about allowing someone or something to access a resource and perform actions on it. Here are some terms used when describing it:
Securables
Securable is mainly a resource which we can assign permissions. SQL Server has securables at multiple level of a hierarchical architecture. The hierarchy starts from the server level which includes securables like Endpoints, Logins, Server Roles and Databases. These securables are called as server-level securables as well as server scope securables.
Next level of the hierarchy is the database. Database-level or database scope securables includes items like Users, Database Roles, Certificates and Schemas.
SQL Server includes securables at Schema level too. They are called as schema scope securables that includes resources like Tables, Views, and Procedures.
Principals
The someone or something that perform actions on securables is called as a Principal. There are three types of principals related to SQL Server security: Window's Principals, SQL Server Principals, and Database Principals.
Window's principals and SQL Server principals are considered as server level principals. Windows level principals are generally domain or local server user accounts or groups that are used to connect with SQL Server instance. Authentication is done by either local server or domain controller, and SQL Server trusts the account without performing authentication. SQL Server level principals are logins created at SQL Server instance and authentication is done by SQL Server itself.
Database principals includes database users, database roles and application roles.
** Some principals are also securables. As an example, Login is a principal as well as a securable. It is a principal that because it can access the SQL Server instance and it is also a securable because there are actions that can be performed on it such as enabling and disabling that require permission.
Permissions
Permissions allow principals to perform actions on securables. There are two types of permissions related to SQL Server: Statement permission and Object Permission.
Statement permissions refer actions that can be performed by executing a statement. The principal creating a table using CREATE TABLE statement with CREATE TABLE permission is an example for it.
Object permissions refer actions that can be performed on securables. A principal having SELECT permission on a table is an example for this.
This image shows how these concepts are worked together. Note that the image has been taken from an article in TechNet Magazine. You can refer the article at: https://technet.microsoft.com/en-us/magazine/2009.05.sql.aspx

Tuesday, February 24, 2015
Gartner Magic Quadrant 2015 for Business Intelligence and Analytics Platforms is published
Gartner has released its Magic Quadrant for Business Intelligence and Analytics platforms for 2015. Just like the 2014 one, this shows business intelligence market share leaders, their progress and position in terms of business intelligence and analytics capabilities.
Here is the summary of it;

This is how it was in 2014;

As you see, position of Microsoft has been bit changed but it still in leaders quadrant. As per the published document, main reasons for the position of Microsoft are strong product vision, future road map, clear understanding on market desires, and easy-to-user data discovery capabilities. However, since the Power BI is yet-to-be-completed in terms of complexities and limitations, and its standard-alone version is still in preview stage, including some key analytic related capabilities (such as Azure ML), the market acceptance rate is still low.
You can get the published document from various sites, here is one if you need: http://www.birst.com/lp/sem/gartner-lp?utm_source=Birst&utm_medium=Website&utm_campaign=BI_Q115_Gartner%20MQ_WP_Website
Subscribe to:
Posts (Atom)