One of the important assets to an organization is data, because it holds valuable information related to the business, such as customers info, products info, financials info and info related to operations performed. In most businesses, downtime is unacceptable, hence take all possible measures to make sure that data is available, protected and recoverable in the event of a disaster or failure. Organizations deploy different solutions such as high-availability solutions, disaster recovery solutions and backup strategies for addressing these requirements. High-availability and disaster recovery solutions are not common with all organizations but backup strategies are the most common implementation for protecting data.
This post speaks about one of the best products; CloudBerry Backup that can be used for backing up Microsoft SQL Server databases to cloud storage accounts with almost all backup features offered by SQL Server.

CloudBerry Backup for SQL Server allows you to perform your backup operations as per the strategy you have planned. Plan could be a simple Full backup, or it could be a combination of Full, Differential, and Transaction Log backups based on RPO and RTO required by the business. You may encrypt it, you may compress it and most importantly you may expect point-in-time restoration in case of data-error or a failure. Not only that, you may want to store your backups in a cloud storage account such as Microsoft Azure or Amazon, or OneDrive, making sure backups are secured and protected. Yes, you can satisfy some of these requirements using functionalities provided with SQL Server but not all. For example, there is no direct way of placing backups into a different cloud storage account other than Azure. It is also available only with SQL Server 2012 SP1 or later, hence requires additional coding if it needs to be done with a prior version. Good news is, all these requirements can be satisfied with the CloudBerry Backup product regardless of the SQL Server version. Not only that, it does not require administration knowledge allowing even a beginner to perform backup operation as per the strategy established.
Let's see how this product works and how easily we can backup our databases.
CloudBerry Backup can be downloaded from following page in CloudBerry Lab site.
http://www.cloudberrylab.com/microsoft-sql-server-cloud-backup-software.aspx
Once the download is completed, install it and open it. You will get the product activation window, if you have the license key, enter it and get it activated, else you con continue with
trial version clicking
Continue Trial button.
CluoudBerry Backup opens with its
Welcome window. You can create your backup plan by clicking either
MS SQL Server button in the
Home ribbon or
Backup SQL Server button in the welcome screen.
Before start creating the plan, you need to prepare for two things; backup strategy and cloud storage account. Let's plan on
AdventureWorks database and
Microsoft Azure as the storage. If you need, you can use your own database, else download
AdventureWorks2014 and restore it as AdventureWorks2014_New for testing. Assume that backup plan as per the RPO and RTO is as follows;
- Full database backup - every Saturday - 4:00am
- Differential backup - week days - 14:00am
- Transaction log backup - week days - every hour - day time
If you already have an account with Microsoft Azure, use it for creating a storage, else create an account and then create a storage. Here is my Microsoft Azure Storage configured.
Everything is ready, let's start creating the plan over a database AdventureWorks2014_New. Click on Backup SQL Server button in Welcome screen. It opens Welcome screen of MS SQL Server Backup Plan Wizard.
Click on Next to continue. Next screen is for selecting the Cloud Storage account. Good thing with CloudBerry Backup is, it allows us to select our preferred cloud storage account from a lengthy list without just offering one platform. Let's select Azure for this.
You need to configure Azure account with this. Select , it opens a window for entering account details. Note that it needs a container too. Once the Display Name, Account and Shared key are entered, select in the Container dropdown and give a name for it.
Click
OK twice and click on
Next to continue. You will get screens for naming the plan, selecting the SQL Server with credentials and selecting the database.
As you see with the last scree, you can either select one database or multiple databases. Since the plan is for one database, select the one you need. Click on
Next to continue. Next option is for encrypting and compressing the backup.
CloudBerry backups support encrypting and compressing on almost all versions of SQL Server starting from SQL Server 2000.
Next screen is for selecting or configuring purging options. You can either accept the default or can configure as you want.
Click on
Next to continue. This screen is for selecting the schedule with options. This screen allows you to take a backup without creating a schedule or a plan, schedule it for a specific time, go for a general strategy with a predefined templates or go for a customized schedule. Not only that, this has two more additional , important options
Stop the plan if it runs for n hours and
Run missed scheduled backup immediately when computer starts up. This is something we do not get with general backup in SQL Server. Since we need a customized plan, let's select
Recurring (advanced schedule).
Next screen is for executing additional operations before performing the backup and after performing the backup. It allows you to select files like
exec, bat files. If you have anything to be done, add them with this screen.
Next screen is for configuring notifications. Various options are given, email notifications can be set up either using CloudBerry facility or using SMTP configured. In addition to that, entries can be made to
Windows Event Log too.
Done. Click on
Next to see the
Summary. Then click on
Next and
Finish selecting
Run backup plan now.
Plan is created. It shows you the details of the plan and
Next Run Time.
It allows you to take a backup even though it is scheduled. If you click on
Run backup now, it will take a full backup and place in your Azure storage.
Since we have enabled notification, this sends us an email;
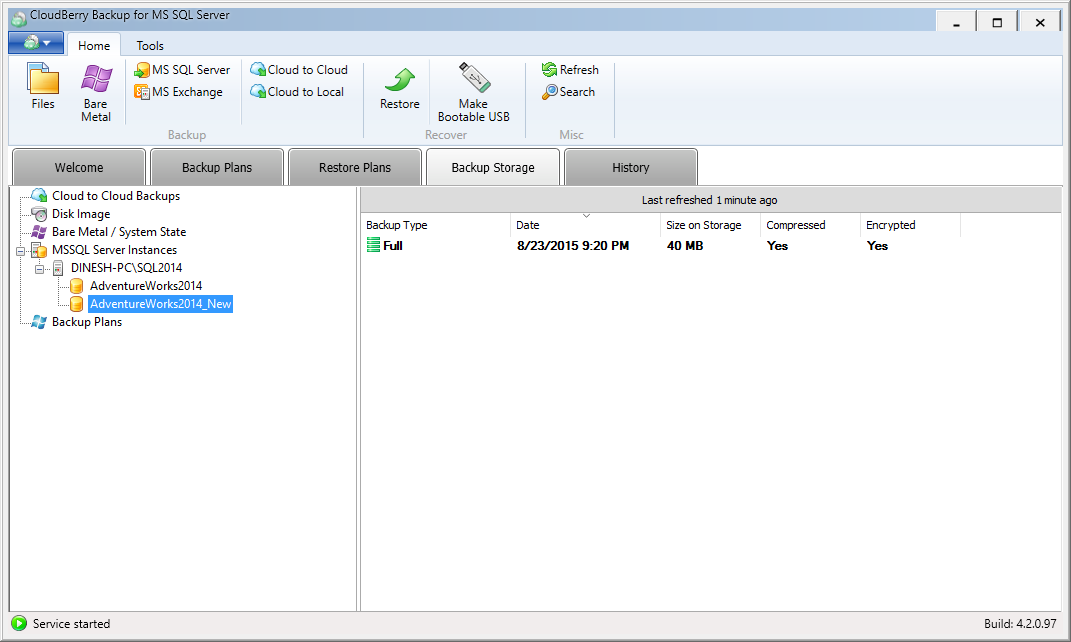
You can see how files are created and placed them in your storage account. If you use Microsoft Azure, then portal can be used for seeing files in the container or a tool like
CloudBerry Explorer for Azure Blob Storage can be used.
Restoring databases from
CloudBerry Backup is an easy task. It allows you to either restore a backup from a stored backup or create a plan on restoration. Point-In time restoration is also possible with this and it will pick the right files based on the date and time given. Here are few important screens of restore operations;
In addition to the screens above, screens are there for decryption, server selecting, emailing, etc.
As you see, it is really easy to manage your SQL Server backup strategies with
CloudBerry Backup. If you still thinking why should you go for this tool, consider following;
- Easy management and scheduling, plan can be simply created.
- Any cloud storage, not just one. Storing them directly to Azure without doing any configuration to the instance.
- Encryption and compression on any version of SQL Server without creating master keys and encryption keys.
- Purging options
- Pre and post actions
- Notification facility even without SMTP configuration.
- Backup file management in the container configured.